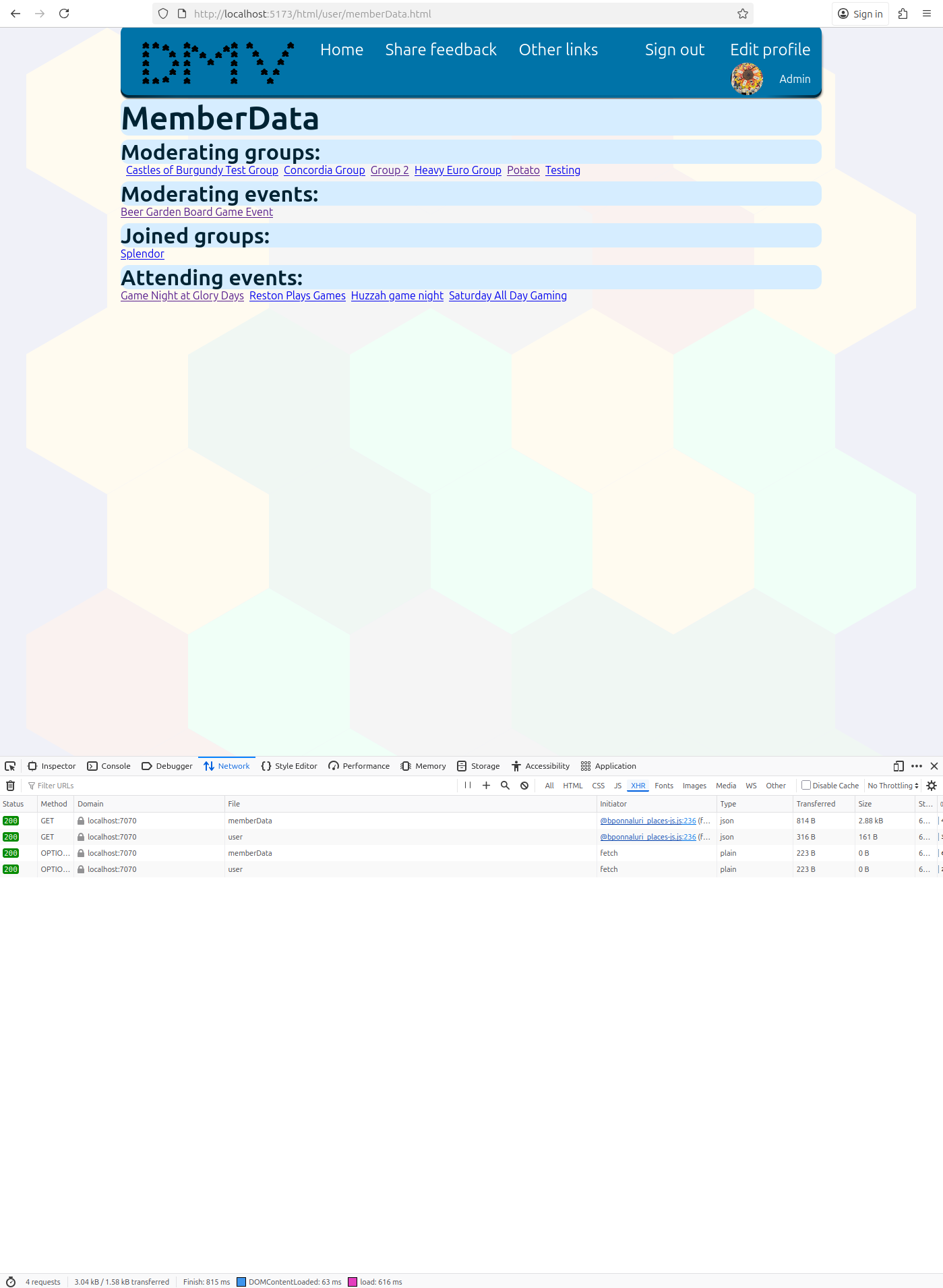
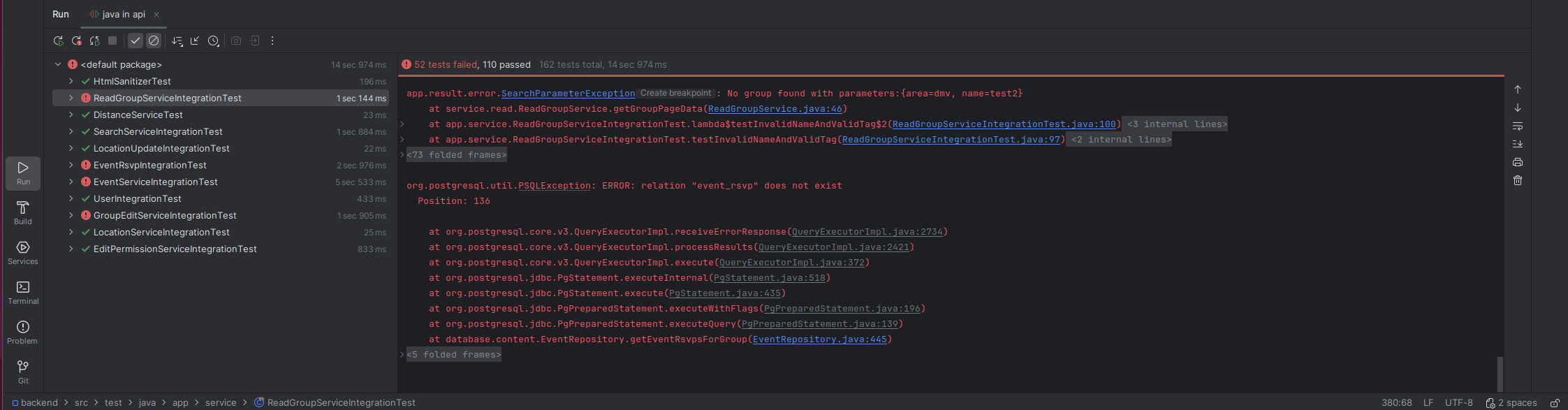
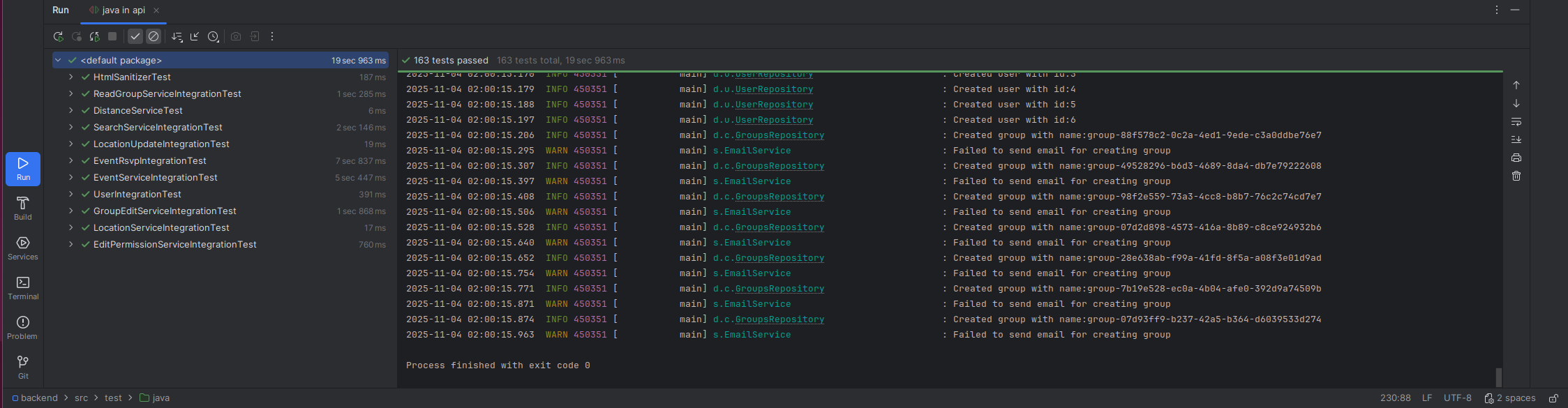
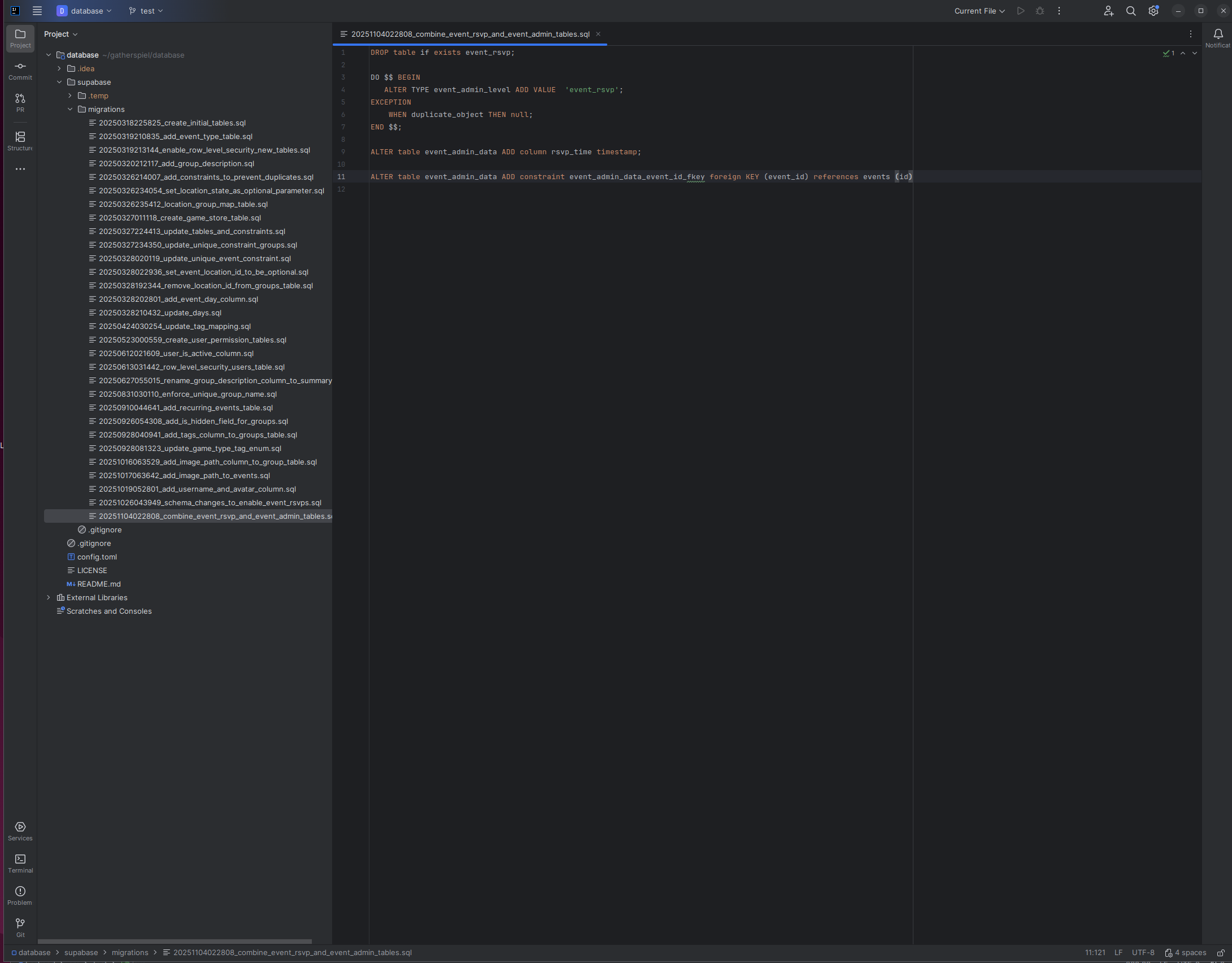
I was looking at two JavaScript libraries, reactive, and ripple.js that use view models to dynamically render html. This made me think about the design of my framework, places.js, which uses a state based approach like the following example.
import {BaseDynamicComponent} from "@bponnaluri/places-js";
import {IS_LOGGED_IN_KEY, LOGIN_STORE} from "../../data/auth/LoginStore.ts";
export class OpenCreateGroupComponent extends BaseDynamicComponent {
constructor() {
super([{
componentReducer:(data:any)=>{
return {
[IS_LOGGED_IN_KEY]: data?.loggedIn
}
},
dataStore:LOGIN_STORE
}]);
}
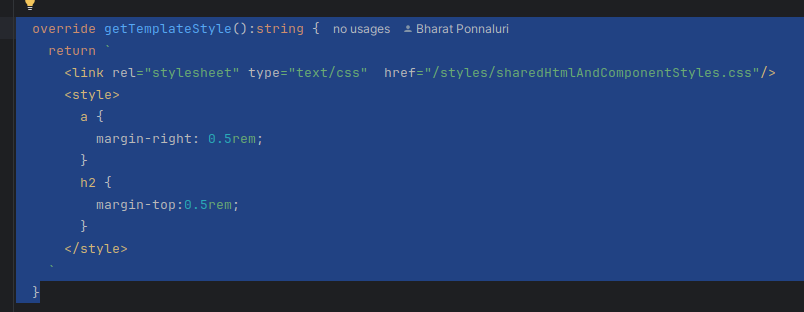
override getTemplateStyle():string{
return `
<link rel="stylesheet" type="text/css" href="/styles/sharedHtmlAndComponentStyles.css"/>
<style>
a {
color: white;
text-decoration: none;
}
</style>`
}
render(data: any){
const url = data[IS_LOGGED_IN_KEY] ?
`html/groups/create.html` :
`/html/users/createAccount.html?message=Register_an_account_and_log_in_to_create_a_group`
return `
<a href ="${url}">Create group</a>`
}
}The data passed into the render method is a regular JavaScript object without type checking. For example, in the component below, if I tried to render the url using the templated string <a href ="${data.url}">Create group</a>`, the component would render a link with an undefined value.
Adding a view model would be one way of adding type checking to this code. I think it would also provide additional value for more complex components. However, I don’t think I should add view models to places.js.
The additional code needed to create view models would mean increased costs with maintenance complexity. Having less code means reduced maintenance complexity.
Adding view models to places.js would mean bugs in the framework that would cost time to fix. The extra complexity would also make it more difficult to make necessary updates to places.js in the future.
I want to make the source code of dmvboardgames.com and places.js approachable to anyone with a basic understanding of CSS, HTML, and Javascript. Adding view models would make the code less approachable.
- The additional code needed to create view models would mean increased costs with maintenance complexity. Having less code means reduced maintenance complexity.
- Adding view models to places.js would mean bugs in the framework that would cost time to fix. The extra complexity would also make it more difficult to make necessary updates to places.js in the future.
- I want to make the source code of dmvboardgames.com and places.js approachable to anyone with a basic understanding of CSS, HTML, and Javascript. Adding view models would make the code less approachable.
- If a developer decides to use view models with places.js, they can extend the BaseDynamicComponent class in places.js to implement view models. As a general rule, I think it is better for other developers to extend the framework to meet the needs of the product they are building. If I implement view models, it is likely that I won’t implement them in a way that precisely meets the needs of other developers. Also, for developers who decide not to use view models, they will be unnecessary complexity. If I add support for the optional use of view models, I’ll have to spend more time maintaining places.js , which will mean I have less time to focus on improving the quality of places.js.
It has been around a month since I last made an update to places.js. Over the past month, I have been actively using places.js to develop new UI components for dmvboardgames.com, and there haven’t been any bugs on the website related to places.js. Modifying a code that has been working reliably for an update that may not be useful is an unnecessary risk.
I’m also making significant changes to the backend to support users joining groups, and I’ll likely be making additional changes. These changes are likely to have bugs, and making changes to places.js will obscure the source of bugs. It is normal to have bugs in software, and it’s impossible to consistently write 100% bug free code on the first try. On the other hand, steps can be taken to make sure the source of a bug can be quickly identified, so that a change can be made to fix it.
If a developer decides to use view models with places.js, they can extend the BaseDynamicComponent class in places.js to implement view models. As a general rule, I think it is better for other developers to extend the framework to meet the needs of the product they are building. If I implement view models, it is likely that I won’t implement them in a way that precisely meets the needs of other developers. Also, for developers who decide not to use view models, they will be unnecessary complexity. If I add support for the optional use of view models, I’ll have to spend more time maintaining places.js , which will mean I have less time to focus on improving the quality of places.js.
To add type safety in the future, I think an alternative solution could be to look into somehow leveraging TypeScript as places.js already uses TypeScript.
In the immediate future, I think updating the constructor to use an updated reducer would be a good way of reducing complexity.
componentReducer:(data:any)=>{
let url = "html/groups/create.html"
if(data?.loggedIn){
url = "/html/users/createAccount.html?message=Register_an_account_and_log_in_to_create_a_group"
}
return {openUrl:url}
},
Then, the render method could be rewritten as follows.render(data: any){
return ` <a href ="${data.openUrl}">Create group</a>`
}